Conseil Recherche Innovation du Greta Auvergne - Agence 43
Conseil Recherche Innovation du Greta Auvergne - Agence 43Travaillez pour Google, c'est gratuit.
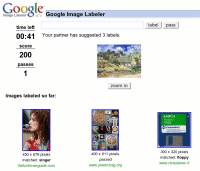 Il y a quelques semaines, Google lançait un jeu original (Google Image Labeler) dont le principe est assez simple. Le joueur se rend sur le site. Un autre joueur, connecté au même moment, lui est attribué aléatoirement de façon à créer une équipe. Les deux joueurs n'ont pas la possibilité de se connaître. Ensuite le jeu commence. Les deux joueurs de l'équipe reçoivent sur leur écran une même image (par exemple une mouette blanche dans le ciel bleu) et doivent en quelques secondes fournir des mots-clefs permettant de décrire cette image. L'équipe marque des points pour chaque mot-clef trouvé en commun par les deux joueurs. Par exemple Joueur 1 donne "oiseau blanc ciel bleu" et Joueur 2 "mouette blanche ciel", les deux joueurs gagneront 1 point grâce à "ciel". Puis une autre image s'affiche et tout recommence, pendant la minute trente que dure la partie. Le but final étant de marquer le plus de points, et de monter dans le classement général.
Il y a quelques semaines, Google lançait un jeu original (Google Image Labeler) dont le principe est assez simple. Le joueur se rend sur le site. Un autre joueur, connecté au même moment, lui est attribué aléatoirement de façon à créer une équipe. Les deux joueurs n'ont pas la possibilité de se connaître. Ensuite le jeu commence. Les deux joueurs de l'équipe reçoivent sur leur écran une même image (par exemple une mouette blanche dans le ciel bleu) et doivent en quelques secondes fournir des mots-clefs permettant de décrire cette image. L'équipe marque des points pour chaque mot-clef trouvé en commun par les deux joueurs. Par exemple Joueur 1 donne "oiseau blanc ciel bleu" et Joueur 2 "mouette blanche ciel", les deux joueurs gagneront 1 point grâce à "ciel". Puis une autre image s'affiche et tout recommence, pendant la minute trente que dure la partie. Le but final étant de marquer le plus de points, et de monter dans le classement général.
Au delà de ce jeu anecdotique qui peut occuper quelques minutes des millions d'utilisateurs, Google a trouvé un moyen efficace et gratuit de "tagguer" des images, c'est-à-dire leur attribuer des mots selon un sens commun. Dans l'exemple ci-dessus il y a au moins une certitude c'est la présence d'un "ciel" puisque le mot est cité par les deux joueurs. "oiseau" et "mouette" statistiquement apparaissent ensemble dans de nombreuses pages (essayez de taper ces deux mots dans Google), donc c'est une information intéressante même si elle n'est pas totalement fiable : il y a probablement un oiseau dans l'image. Idem pour "ciel" et "bleu". Et "blanc" et "blanche" ne font aucun mystère pour Google, qui sait certainement travailler sur les racines des mots. Bref, en quelques secondes Google obtient des informations sur cette image, qui même si elles ne sont pas totalement fiables, pourront être affinées en reproposant la même image à une autre équipe. Impossible de biaiser le système, car il faudrait un consensus entre les joueurs, ce qui est impossible puisqu'ils ne se connaissent pas.
 Il y a quelques semaines, Google (encore) lançait (encore) un nouveau service : Google Custom Search. Le principe est simple, pour résumer rapidement... Chacun peut créer son propre moteur de recherche, à partir d'une sélection de sites. Ensuite la recherche peut s'effectuer sur cet ensemble plutôt que sur le web tout entier ou sur un unique site comme c'est le cas actuellement. Le tout est gratuit pour celui qui crée son moteur (le webmaster) et pour celui qui fera les recherches (le visiteur). Cerise sur le gateau, il est possible de personnaliser l'apparence de la page de résultats.
Il y a quelques semaines, Google (encore) lançait (encore) un nouveau service : Google Custom Search. Le principe est simple, pour résumer rapidement... Chacun peut créer son propre moteur de recherche, à partir d'une sélection de sites. Ensuite la recherche peut s'effectuer sur cet ensemble plutôt que sur le web tout entier ou sur un unique site comme c'est le cas actuellement. Le tout est gratuit pour celui qui crée son moteur (le webmaster) et pour celui qui fera les recherches (le visiteur). Cerise sur le gateau, il est possible de personnaliser l'apparence de la page de résultats.
Il y a une analogie avec le jeu présenté ci-dessus. Google ne va pas se priver d'exploiter les informations issues de ce montage astucieux. De nombreuses petites mains ont déjà commencé à sélectionner des sites qui traitent d'un même thème, et proposent ainsi une recherche thématique (certains parlent de moteurs de recherche verticaux). Google va lancer sa machine à statistiques pour essayer de comprendre ce que ces sites réunis ont en commun, quels mots ils partagent, quels mots reviennent souvent, quel espace du web est lié à cet ensemble de sites et quels mots ce même espace contient, etc. Les statistiques vont pouvoir faire ressurgir des informations importantes, mais cette fois à partir de sous-ensembles ordonnés du web. Il est évident que les recherches récurrentes faites sur le web tout entier vont profiter de ce qu'aura appris Google avec les mêmes recherches faites parmi ces sous-ensembles du web. Bref, toute trace d'ordre est bonne à (ap)prendre dans ce bouillon désordonné d'information qu'est le web.
Google fait donc travailler ses utilisateurs mais c'est de bonne guerre : le service est gratuit, et la seule chose qu'il demande est aux uns de sélectionner des sites qu'ils apprécient, et aux autres de faire des recherches parmi ces sites (qui les intéressent aussi). Les uns et les autres se nourrissent mutuellement, dans la basse-cour "offerte" par Google. Avec son pouvoir grandissant, cela rassure (un tout petit peu) de savoir qu'au delà de la publicité qui le fait vivre, les utilisateurs de tous bords restent une denrée précieuse pour la Grande entreprise, et qu'il faut les ménager. A ma connaissance, Exalead, le petit concurent européen de Google, n'a jamais sollicité les principaux intéressés pour améliorer son service, et doit considérer qu'une observation passive de la sphère internet suffit. Alors que Google, en rendant ses utilisateurs producteurs et actifs, a compris qu'il avait beaucoup à gagner en terme de pertinence des informations reccueillies.
- Connectez-vous ou inscrivez-vous pour publier un commentaire
Commentaires
C'est vrai, qu'il y a je
C'est vrai, qu'il y a je pense un interêt à observer le comportement des utilisateurs de services comme CSE, mais seulement une fois une certaine masse critique atteinte, ceci afin d'éviter le spam.